 Blog
Blog
暑くなったり寒くなったりで、服装の正解がよく分からない日が続いています。
新潟ではそろそろ湿気も気になりはじめ、ビールの消費量がじわじわ増えてきました。
さて、WordPress のサイト内検索はキーワード一致が基本です。
扱いやすい反面、調べたい内容と記事中の表現がズレると、目当ての記事になかなか辿り着けません。
「画像最適化」で探したい記事の本文が「WebP 変換」や「メディア容量削減」と書かれている、というケースです。
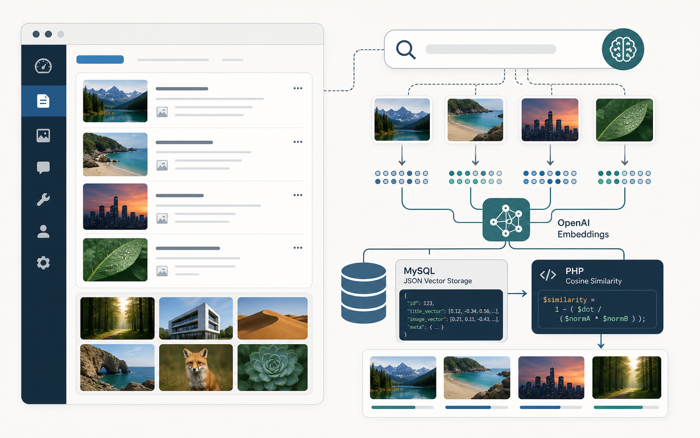
そこで、OpenAI API で投稿や画像を embedding 化し、WordPress の DB に保存して PHP でコサイン類似度検索する、というプラグインを実験的に作ってみました。
本記事ではその構成と、触ってみて感じたことをまとめます。
やりたいこと
出発点は次の 4 点です。
- キーワード一致ではなく意味の近さで検索する
- 専用の Vector DB を持ち込まず WordPress の MySQL だけで完結させる
- 投稿だけでなく画像メディアも同じ検索結果に混ぜる
- 既存サイトに後から入れてもある程度自然に動かす
Pinecone や pgvector を使うほうが本格的なのは間違いありません。
それでも、まずは WordPress だけでどこまで作れるかを見ておきたかった、というのが今回の動機です。
作ったもの
作ったプラグインは WP Native Vector Search です。
ソースコードは GitHub で公開しています。 WP Native Vector Search
処理の流れはシンプルで、次のステップになります。
- 投稿データを OpenAI API で embedding 化する
- embedding を独自テーブルに JSON として保存する
- 検索クエリも embedding 化する
- PHP でコサイン類似度検索する
- score の高い投稿を検索結果として返す
主な機能はおおむね次のとおりです。
- OpenAI による text embedding 生成
- 投稿・固定ページの index 化
- 画像メディアの説明文生成と検索対象化
- 独自テーブルへの vector 保存
- PHP によるコサイン類似度検索
- REST API による検索エンドポイント
- Gutenberg 検索ブロック
- WordPress 標準検索フォームの置き換え
- WP-CLI による既存データの index 化
初期設定では embedding model に text-embedding-3-small、画像説明用の vision model に gpt-4.1-mini を使っています。
DB への保存
プラグインを有効化すると、次の独自テーブルを作成します。
- wp_vector_search_embeddings
保存している主なカラムです。
- post_id
- post_type
- post_status
- content_hash
- embedding
- embedding_model
- dimensions
embedding は JSON 配列にして longtext に格納しています。
専用の Vector DB と比べれば検索性能は当然落ちますが、小規模なサイトやローカル検証なら、テーブル 1 本で済む構成はかなり扱いやすいです。
投稿の index 化
投稿はタイトル・抜粋・本文を結合して embedding 化します。
ここで気を遣ったのが、投稿保存時に OpenAI API を同期で呼ばないことです。
保存リクエストの中で外部 API を叩くと管理画面の挙動が一気に重くなるため、保存中は API を呼ばず、WordPress cron の単発イベントとして index 処理を予約しています。
対象にしているフックは次の 3 つです。
- save_post
- transition_post_status
- deleted_post
save_post と transition_post_status は同じ保存操作で両方発火することがあるため、同じ投稿に対して二重に API を呼ばないよう制御しています。
また、本文と model から content_hash を作っておき、内容が変わっていなければ embedding の再生成をスキップします。
OpenAI API の利用量は、ここでだいぶ抑えられます。
検索の流れ
検索処理は次の順番で進みます。
- 検索クエリを正規化
- OpenAI API でクエリを embedding 化
- DB から保存済み embedding を取得
- PHP でコサイン類似度検索
- score 順に並び替え
- 最小 score 未満を除外
- REST API のレスポンスとして返却
REST API のエンドポイントです。
/wp-json/vector-search/v1/searchリクエスト例です。
{
"query": "WordPress のセキュリティ対策",
"limit": 10
}クエリの embedding は transient で 5 分間キャッシュしています。同じ検索語が短い間に連続で叩かれても、毎回 OpenAI API を呼ばずに済みます。
コサイン類似度検索を PHP で書く
検索の肝になるコサイン類似度検索の計算部分は、PHP で書くと素朴に次のような形になります。
private function cosine_similarity( array $a, array $b ): ?float {
$dot = 0.0;
$norma = 0.0;
$normb = 0.0;
$count = count( $a );
for ( $i = 0; $i < $count; $i++ ) {
$dot += $a[ $i ] * $b[ $i ];
$norma += $a[ $i ] ** 2;
$normb += $b[ $i ] ** 2;
}
if ( 0.0 === $norma || 0.0 === $normb ) {
return null;
}
return $dot / ( sqrt( $norma ) * sqrt( $normb ) );
}やっていることはベクトルの内積を、それぞれのノルムの積で割っているだけです。
次元数が同じであれば素直に値が返ってきますし、片方がゼロベクトルのときだけ null を返してスコアから除外するようにしています。
実装としてはこれで十分動きますが、投稿件数 × ベクトル次元のループを毎回 PHP で回すことになるので、件数が増えると一気に重くなります。
このあたりは後半の「注意点」で改めて触れます。
キーワード検索も少し混ぜる
意味検索だけで運用すると、固有名詞や短い検索語で結果がズレることがあります。
そこで vector score に加えて簡単な keyword boost も入れました。
検索語がタイトルにそのまま含まれていたり、本文に一致する語があったりすれば、少しだけ score を足す、という素朴な仕組みです。
final score = vector score + keyword score本格的なハイブリッド検索ではありません。
それでも、WordPress の記事検索として使うなら、完全な意味検索だけよりキーワード一致を少し混ぜたほうが自然に感じる場面が多く、妥協点としてこの形に落ち着きました。
画像も検索対象にする
今回作ってみて面白かったのが、画像メディアも検索対象に含めた部分です。
画像 embedding を直接扱うのではなく、まず vision model で画像の説明文を生成します。その説明文を text embedding 化し、投稿と同じ検索テーブルに保存する、という構成です。
説明文には、次のような観点を含めるようプロンプトを組んでいます。
- 何が写っているか
- 用途
- 読み取れる文字情報
- 色
- 構図
- 雰囲気
- 関連しそうな検索語
これにより、ファイル名や alt が雑な画像でも、画像の中身に近い言葉で検索できるようになります。
たとえば、こんな検索でも引っかかります。
- CMS の比較表
- 青い背景のロゴ
- 管理画面のスクリーンショット
- WordPress と Headless CMS の図解
生成した説明文は attachment の postmeta に保存し、メディアライブラリ側からも確認できるようにしています。
Gutenberg ブロック
検索 UI として Gutenberg ブロックも用意しました。
フロント側では REST API を呼び出し、検索結果を表示します。投稿とメディアの両方を検索対象に含められ、画像の場合はサムネイル付きで返します。
設定で有効化すれば、WordPress 標準の検索フォームや Core Search ブロックを、この vector search 用フォームに置き換えることもできます。
検索イメージは、こんな感じ
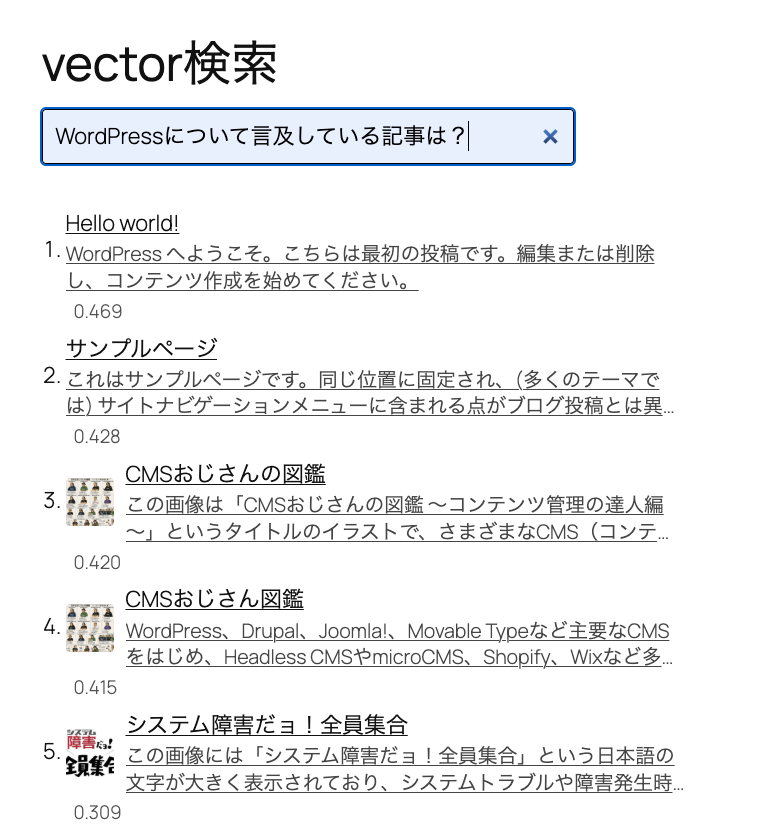
検索イメージは、こんな感じ
注意点
前提として、このプラグインは実験的なプラグインなので、仮に本番運用に使用する場合はいくつか注意点があります。
まず、DB に保存した JSON を PHP で読み出して類似度計算する構成なので、データ量が増えるほど検索コストが上がります。記事やメディアが多いサイトでは、専用の Vector DB や検索基盤に寄せたほうが素直です。
また、検索のたびにクエリ embedding を作るため、OpenAI API の利用量がそのまま発生します。キャッシュや rate limit は入れていますが、公開サイトで使う場合はアクセス数を見ながらの調整が必要です。
画像説明文の生成も同様で、メディアライブラリの大きいサイトでは、一括処理のタイミングや対象範囲を決めておかないと、時間もコストも読みにくくなります。
まとめ
WordPress の中だけで意味検索を試すために、OpenAI API と PHP のコサイン類似度検索を使ったプラグインを作ってみました。
画像を一度自然言語化してから embedding に通す部分は、WordPress のメディア検索の体感をかなり変えてくれます。
embedding まわりの実験ネタとしても、思っていたより遊びがいがありました。
外部 Vector DB を使わず、embedding を MySQL に JSON として保存する構成でも、小規模な検証であれば意味検索の体験は一通り作れます。
一方で、データ量やアクセス数が増えると、PHP で全件比較する構成には限界があります。
このあたりは実験用と割り切り、本格運用では専用の検索基盤や Vector DB を検討するのが良さそうです。
たとえば WordPress のように MySQL 系の DB を使うサイトであれば、MariaDB の VECTOR 検索はかなり相性が良さそうです。
MariaDB 11.7 から VECTOR 型と VEC_DISTANCE_* 系の関数、ANN インデックスが組み込みで使えるようになっていて、フルテキスト検索とベクトル検索を組み合わせるハイブリッド検索もサポートされています。
今回のように PHP 側で全件コサイン類似度検索を回すのではなく、SQL に検索を寄せられるので、本番運用ではこちらに置き換えるのが現実的だと感じています。
現場からは、以上です。
