ふきのとう、木の芽、タケノコなど、春の山菜が採れ始めました。この時期、週末はタケノコのアク抜きをしながら木の芽をつまみにセゾンをいただくのが楽しみとなっています。
さて、私が入社後に初めて関わった案件でMTのデータベースを検索するためのバックエンドAPIをAWS SAMベースで構築しました。先日無事ローンチできましたので、備忘録として気をつけた点などをまとめておきたいと思います。
さて、私が入社後に初めて関わった案件でMTのデータベースを検索するためのバックエンドAPIをAWS SAMベースで構築しました。先日無事ローンチできましたので、備忘録として気をつけた点などをまとめておきたいと思います。
記事の取得、一覧の返却、条件での絞り込みといった処理は、1本ずつ見るとどれも比較的素直です。ただ、そこに認証、利用者ごとの扱い、レスポンス形式の統一、データベース接続、デプロイ方法が絡んでくると話が変わります。機能追加も入りやすいので、気づくと「それぞれは単純なのに、全体では追いにくい」状態になりがちです。
今回は要件の詳細には触れませんが、構成をどう切ったか、どこを共通化したか、運用しやすくするために何を揃えたかをまとめてみました。やりたかったことは、ざっくり3つです。
- 検索系APIを機能単位で分けつつ、共通処理は散らばらないようにする
-
ローカル開発、テスト、デプロイまでの流れを揃える
-
データベース接続や公開経路を含めて、無理のない運用構成にする
全体の構成
今回のAPI群は、単一データの取得だけでなく、複数条件での検索、関連記事の取得、利用ログの記録といった役割を持っています。ひとつの関数に寄せすぎると見通しが悪くなりやすく、逆に細かく分けすぎると共通処理が散らばります。そこで、エンドポイントごとにLambdaを分ける一方で、入力バリデーション、レスポンス生成、データベース接続のような横断処理は共通モジュールに切り出しました。
インフラ定義にはAWS SAMを使っています。こうすることでAPI Gateway、Lambda、VPC設定、セキュリティグループ、環境ごとのパラメータをテンプレートで管理できるので、アプリケーションコードとインフラ変更を同じ流れで追えます。検索系APIは条件追加や派生APIが出やすい領域で、変更箇所が散っているとそのたびにレビューやデプロイが重くなります。SAMに寄せたことで、API追加時の変更単位を揃えやすくなりました。
構成を単純化すると、次のようなイメージです。
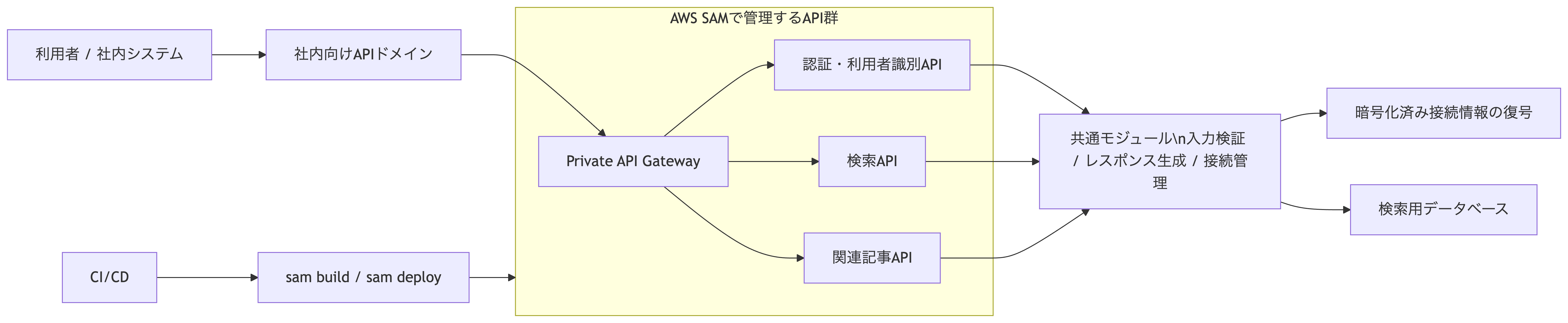
検索系APIをAWS SAMで管理し、共通処理を集約しながら、限定した経路でデータベースへ接続する構成です。仕様確認、テスト、デプロイまでを同じ流れで扱えるようにしています。
Lambdaは細かく、共通処理はまとめる
実装では、検索用途ごとにLambdaを分けています。単一データの取得、一覧検索、カテゴリ別の検索、関連記事の取得という具合に責務を切りました。
意識したのは、全部を汎用化しすぎないことです。検索系APIは似た形になりやすいので、つい共通化を進めたくなります。ただ、無理にひとつの抽象へ押し込むと読みにくくなります。
"共通化の範囲を広げすぎると、今度は共通モジュール自体が肥大化して追いにくくなる。どこまで共通にするかの線引きが、長期的な保守性を左右する。"
共通化したのは主に次の部分です。
- 入力値の検証
- レスポンス形式の統一
- データベース接続
- 検索条件の正規化
検索条件の組み立てや取得ロジックの差分は、用途ごとの実装に残しています。この線引きのおかげで、各APIの責務を保ちつつ、変更しやすい状態を維持できました。
検索APIでは入口を揃える
検索系のAPIでは、入口の整理を重視しました。数値範囲、配列の形式、文字列の扱い、ソート順の指定などを、できるだけハンドラの入口で検証するようにしています。曖昧な入力をそのまま下流へ流すと、検索条件の組み立てやSQLがすぐ読みにくくなるからです。バリデーションを先に済ませておけば、検索ロジック側は何を取るかに集中できます。
たとえば、検索条件を受け取るAPIでは、リクエストボディを最初にパースし、件数、オフセット、絞り込み条件、並び順を順番に検証しています。異常系はその場で返し、後続の処理には正規化済みの値だけを渡す形です。条件が増えてもどこへ足すべきかが分かりやすくなり、地味ですが大事な整理です。
データベース接続は早めに整理しておく
データベース接続情報は、暗号化した値を実行時に復号して使う構成にしています。接続情報をそのままコードや設定ファイルへ置きたくなかったためです。接続処理は共通モジュールにまとめ、プールの取得、クエリ実行、クローズ処理の呼び出し方を揃えました。
サーバーレス環境では、機能追加のたびに接続まわりの実装が微妙にずれていくことがあります。ここを共通化しておくと、修正時の影響範囲をかなり読みやすくできます。
"検索ロジックを書いているときは条件分岐や取得処理に意識が向くが、障害時に調べることが多いのは接続や設定まわりだ。だからこそ、ここは最初に整理しておく価値がある。"
APIは公開経路も含めて設計する
検索APIは、単にLambdaとデータベースがつながればよいわけではありません。どこから呼べるのか、どこまで公開するのかも含めて設計する必要があります。今回の構成では公開範囲を必要最小限に絞り、利用者識別に必要な情報をアプリケーション側で扱えるようにしました。詳細な構成は伏せますが、アプリケーションコードだけでなく、ネットワーク上の到達経路まで合わせて考える前提で組み立てています。
コードだけ整っていても、公開面の設計が曖昧だと運用時に問題がおきます。検索系APIに限らず、API全般で大事なポイントです。
OpenAPI、ローカルDB、SAMで開発の流れを揃える
開発体験の面では、早い段階で仕様確認ができることを重視しました。API仕様はOpenAPIで定義し、モックサーバーでインターフェース確認ができるようにしています。検索系APIはフロントエンドや周辺システムと並行で進むことが多いので、実装前からレスポンスの形を共有できるのは助かりました。仕様が先に見えるだけでも、認識のズレをかなり減らせます。
ローカルでは、コンテナ上にデータベースを立ててテストや疎通確認ができるようにし、SAMのローカル実行と組み合わせることでクラウドへ上げる前に手元で流れを確認できるようにしています。実装、仕様確認、テストの往復が軽くなり、変更を入れたあとどこまで確認すればよいかが分かりやすくなったのが大きかったです。
テストとCI/CDはできるだけ素直にする
テストはNode.js標準のテストランナーを使っています。エンドポイントごとのユニットテストに加え、共通モジュールの振る舞いも分けて確認する構成です。検索APIでは、実装の中身そのものよりも「この条件ならこう返る」が崩れていないことの方が重要なので、振る舞いベースで確認しやすいようにハンドラと共通処理の境界を意識して設計しました。
CI/CDはマージリクエスト時にテストを実行し、ブランチに応じて環境へデプロイする流れです。特別な仕組みではありませんが、流れを単純に保つことには意味があります。サーバーレス構成は更新しやすいぶん、開発者が迷わず使えることの価値が大きいからです。
やってみてよかったこと
今回の取り組みで特によかったのは、API実装、インフラ定義、ローカル検証、デプロイまでの流れがひと続きになったことでした。検索要件はどうしても変わります。途中で条件が増えたり、似たAPIが必要になったり、返し方を調整したくなったりします。そうした変化に対して、どこを直せばよいかが分かりやすい構成になっていると、追加開発の負担がかなり違ってきます。
AWS SAMは、単にLambdaをデプロイするための道具というより、API開発とインフラ管理の境界を整理するための土台として使いやすいです。機能追加と運用改善が続く領域では特に相性がよいと思っています。
おわりに
検索系バックエンドAPIは、1本ずつ見ると素直でも、全体ではじわじわ複雑になりがちです。Lambdaの責務を分けつつ、共通処理はまとめ、ローカル検証からデプロイまでの流れを揃えたことで、機能追加や修正のときに変更箇所を追いやすくなりました。検索条件の拡張や可観測性の改善など、今後も手を入れる余地はありますが、土台をコードとして整理しておけたのは大きかったです。
検索系APIは一度作って終わりではなく、使われ方に合わせて変わっていくものです。最初の構成をきちんと整理しておくことが、その後の開発速度に影響してきます。
現場からは、以上です。
